Chatbot with NextJS & OpenAI
Creating a Retrieval-Augmented Generation (RAG) application allows you to leverage the capabilities of language models while grounding their responses in specific, reliable information you provide to the model.
This guide will walk you through building a RAG application using NextJS for the web framework, the OpenAI API for the language model, and Dewy as your knowledge base.
By the end of this tutorial, you'll understand how to integrate these technologies to reduce hallucinations in language model responses and ensure the information provided is relevant and accurate.
Getting Started
This guide will walk you through how to create a simple RAG-powered chatbot. The final code is available as an example if you'd rather skip to the end and start hacking 😉.
Prerequisites
- Basic knowledge of JavaScript and React.
- A NextJS environment set up on your local machine.
- A copy of Dewy running on your local machine (see Dewy's installation instructions if you need help here).
- Access to the OpenAI API platforms.
Step 1: Set Up Your NextJS Project
-
Initialize a new NextJS project: Create a new NextJS app by running the following command in your terminal:
npx create-next-app@latest my-rag-appNavigate into your new project directory:
cd my-rag-app -
Install required packages: Install client librarires for the OpanAI API and Dewy.
npm install openai dewy-ts ai -
Prepare environment variables: Set up environment variables for the OpenAI API key and your Dewy instance. Create a
.env.localfile in the root of your NextJS project and add the following lines:OPENAI_API_KEY=<your_openai_api_key_here>
DEWY_ENDPOINT=localhost:8000
DEWY_COLLECTION=main
Step 2: Create an API endpoint to add documents
import { Dewy } from 'dewy-ts';
export const runtime = 'edge'
// Create a Dewy client
const dewy = new Dewy({
BASE: process.env.DEWY_ENDPOINT
})
export async function POST(req: Request) {
// Pull the document's URL out of the request
const formData = await req.formData();
const url = formData.get('url');
const document = await dewy.kb.addDocument({
collection: process.env.DEWY_COLLECTION,
url,
});
return NextResponse.json({document_id: result.id})
}
This API handler receives a form containing a document and indexes it in the knowledgebase. Dewy takes care of downloading the document, extracting information from it and making that information available as searchable chunks.
Step 3: Create an API endpoint for chat generation
-
Create a generation function: This function will take the user's query and the retrieved documents from Dewy, and send a request to the OpenAI API to generate a response. The key is to format the prompt to include relevant information from the retrieved documents.
app/api/chat/utils.tsximport OpenAI from 'openai';
import { Dewy } from 'dewy-ts';
// Create Dewy and OpenAI clients
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY
})
const dewy = new Dewy({
BASE: process.env.DEWY_ENDPOINT
})
export async function generate({query}) {
// Search Dewy for chunks relevant to the given query.
const context = await dewy.kb.retrieveChunks({
collection: process.env.DEWY_COLLECTION,
query: query,
n: 10,
});
// Build an augmented prompt providing the retrieved chunks as context for the LLM.
const prompt = [{
role: 'system',
content: `You are a helpful assistant.
You will take into account any CONTEXT BLOCK
that is provided in a conversation.
START CONTEXT BLOCK
${context.results.map((c: any) => c.chunk.text).join("\n")}
END OF CONTEXT BLOCK`,
} ]
// Call the OpenAI chat completion API to generate a response
const messages = [...prompt, [{role: 'user': content: 'Tell me about RAG'}]]
const res = await openai.chat.completions.create({
messages,
model: 'gpt-3.5-turbo',
temperature: 0.7,
})
return res
} -
Create the route handler: This function handles chat messages by calling the generation function we just created and streaming back the generated response in real-time.
app/api/chat/route.tsximport { OpenAIStream, StreamingTextResponse } from 'ai';
import { generate } from "./utils";
export async function POST(req: Request) {
const json = await req.json()
const { messages } = json
// Generate a response to the updated conversation
const response = await generate(messages);
// Convert the response into a friendly text-stream
const stream = OpenAIStream(response);
// Respond with the stream
return new StreamingTextResponse(stream);
}
Step 4: Build the Frontend
- Basic form for loading Documents: This component creates a simple form with a text box and submit button, for sending URL's to the document creating route we created earlier.
app/components/AddFromUrl.tsx
import React, { useState, FormEvent } from 'react';
export default function AddFromUrl(props) {
async function onSubmit(event: FormEvent<HTMLFormElement>) {
event.preventDefault()
const formData = new FormData(event.currentTarget)
await fetch('/api/documents', {
method: 'POST',
body: formData,
})
}
return (
<form onSubmit={onSubmit} {...props}>
<input type="text" name="url" placeholder="URL to load..."/>
<button type="submit">Load</button>
</form>
)
} - Create a simple chat UI: Use NextJS pages to build a user interface where users can input their queries. This will involve creating a form in the
pages/index.jsfile.app/page.tsx'use client';
import { useChat } from 'ai/react';
import AddFromUrl from './components/AddFromUrl';
export default function Chat() {
const { messages, input, handleInputChange, handleSubmit } = useChat();
return (
<div className="flex flex-col w-full max-w-md py-24 mx-auto stretch">
{messages.map(m => (
<div key={m.id} className="whitespace-pre-wrap">
{m.role === 'user' ? 'User: ' : 'AI: '}
{m.content}
</div>
))}
<form onSubmit={handleSubmit}>
<input
className="fixed bottom-10 w-full max-w-md p-2 mb-8 border border-gray-300 rounded "
value={input}
placeholder="Say something..."
onChange={handleInputChange}
/>
</form>
<AddFromUrl className="fixed bottom-0 w-full max-w-md p-2 mb-8 border border-gray-300 rounded shadow-xl"/>
</div>
);
}
Try it out!
Build your application and run it locally:
npm run dev
You should see a simple chat UI like the following:
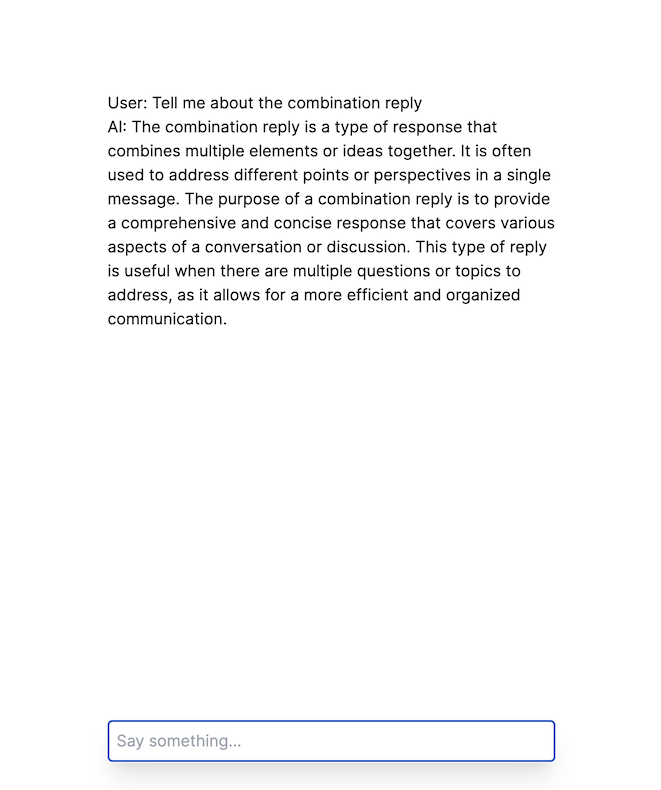
Managing Documents for RAG Using Dewy's Admin Console
In addition to API endpoints for managing documents programmatically, Dewy provides a GUI admin console.
You can see the admin console in a browser at port 8000 (ie https://localhost:8000 if you're running Dewy locally).
Dewy's admin console is designed to streamline the management of documents used for Retrieval-Augmented Generation (RAG) applications. By offering an intuitive interface and comprehensive features, it helps you fine-tune your knowledge bases, ensuring the AI generates responses that are both accurate and relevant. Here's how you can use Dewy's admin console to manage your documents effectively:
Adding a Document
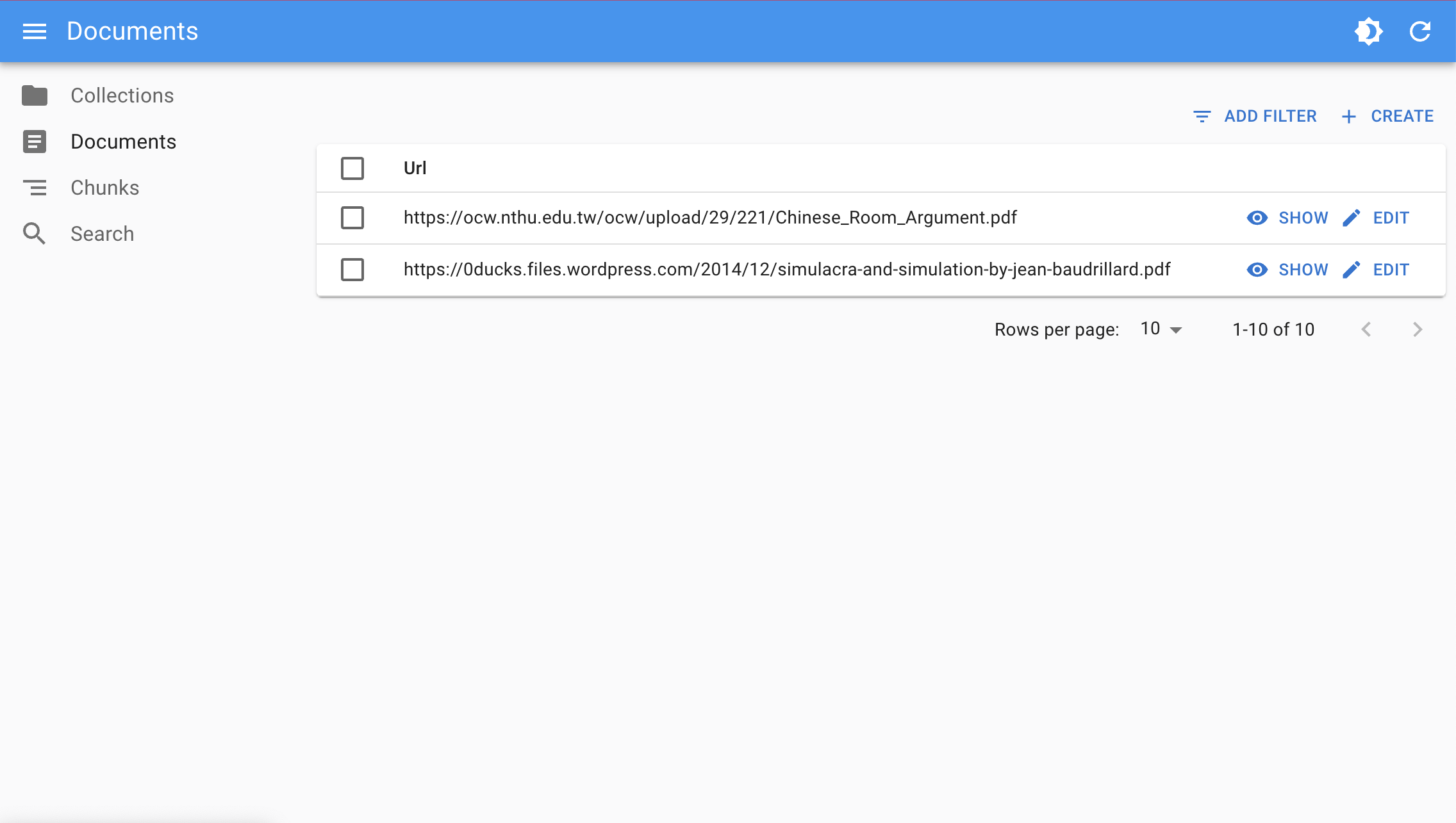
Upload or input new documents into your Dewy knowledge base through the admin console.
Once a document is added, you can immediately observe how it influences the AI-generated results. This is useful for assessing the utility of new information and ensuring it aligns with the desired output quality and relevance.
Exploring Extracted Information
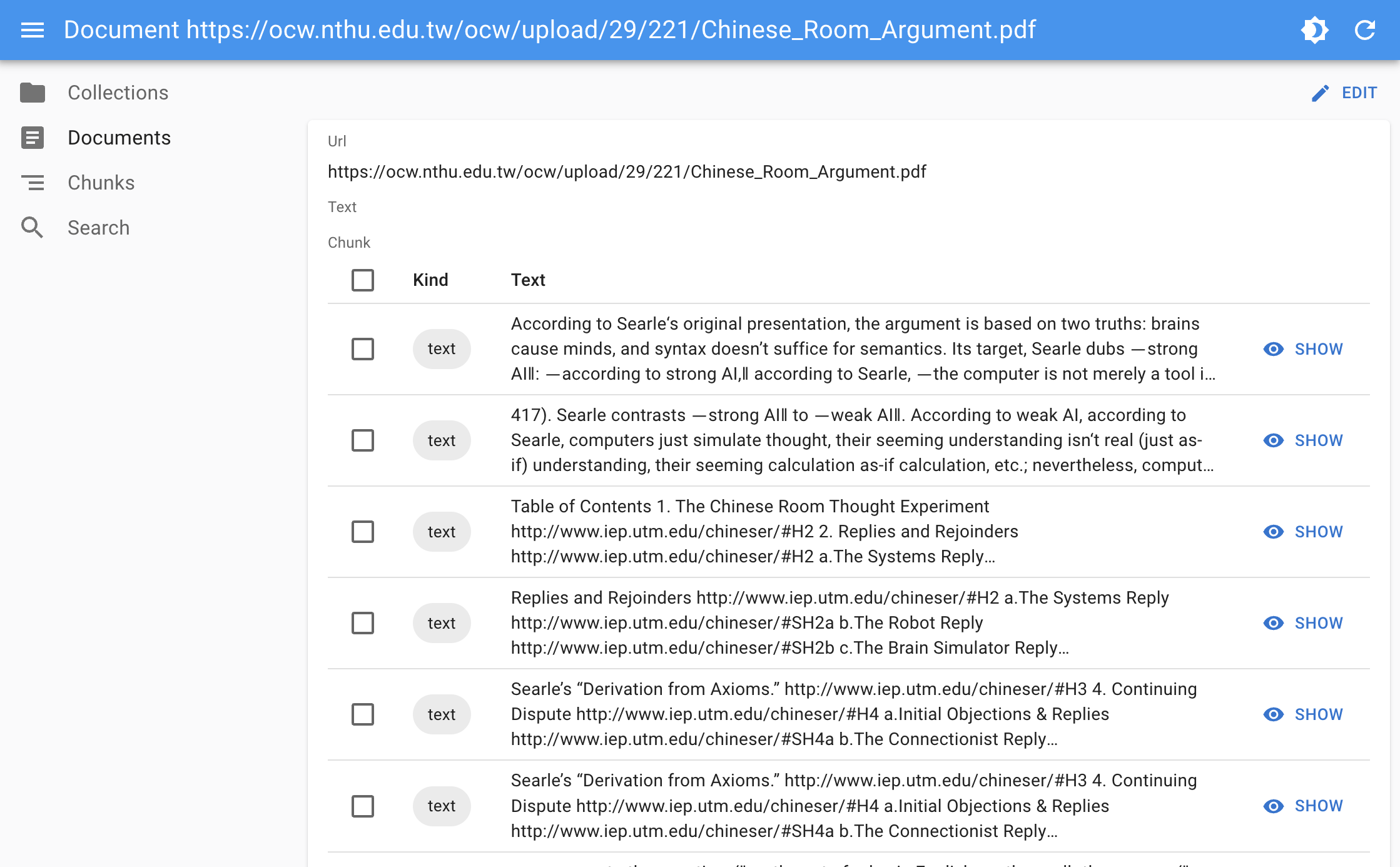
Dewy's console allows you to get into the specifics of how information is extracted from each document. You can view structured data extracted from the text, making it easier to understand how the document might influence generation.
This exploration aids in fine-tuning the extraction process, ensuring that the most relevant pieces of information are highlighted and utilized in the RAG process.
Sample Queries
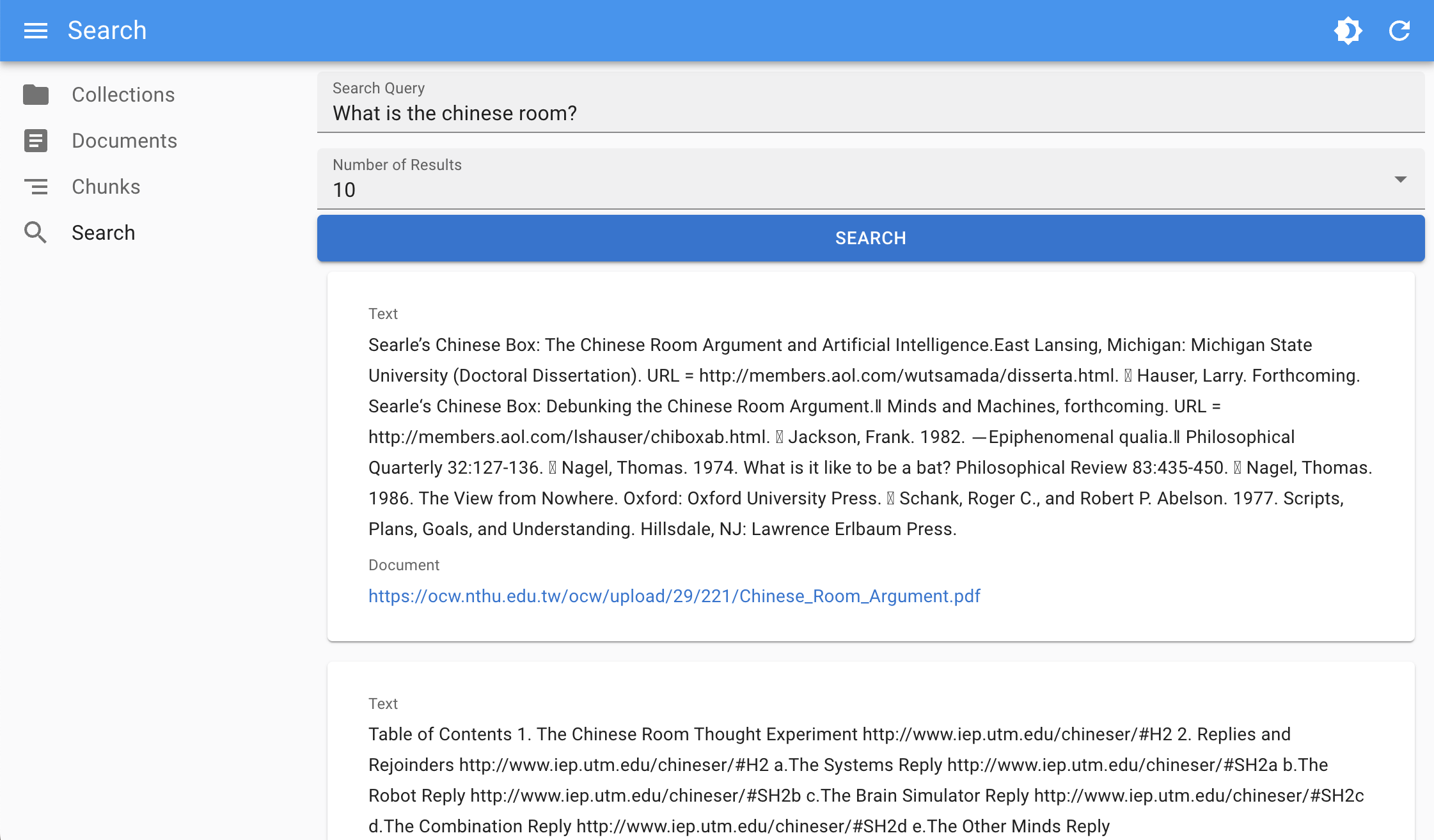
The admin console lets you test sample queries against your knowledge base. This helps when evaluating how well the RAG system retrieves relevant document chunks based on different inputs.
By observing what is returned for each sample query, youd can quickly gauge the effectiveness of your current document set and retrieval algorithms, making it easier to identify areas for improvement.
Conclusion and Key Takeaways
By building this RAG application, you've learned how to reduce hallucinations by providing specific, relevant information to your Gen AI application. This approach mitigates common issues such as hallucinations by ensuring the AI's responses are grounded in accurate information, and it addresses the challenge of managing large documents by intelligently retrieving only the most relevant information for each query.
